

PixAI 的「圖生影片 」功能讓您能透過強大的動畫工具,賦予靜態圖片生命。無論您是新手還是老用戶,都會發現這次的重大升級:更精簡的介面以及能力大幅增強的新模型。本指南將探索更新後的作業流程、比較各模型優勢,並分享撰寫高效提示詞的專業技巧。
讓我們開始探索全新的 PixAI i2v 體驗吧!
介面導覽
i2v 介面設計直觀,方便您精準控制。以下是主要功能說明:
- 左側面板: 拖曳或點擊「上傳圖片」以添加您的原始圖源。

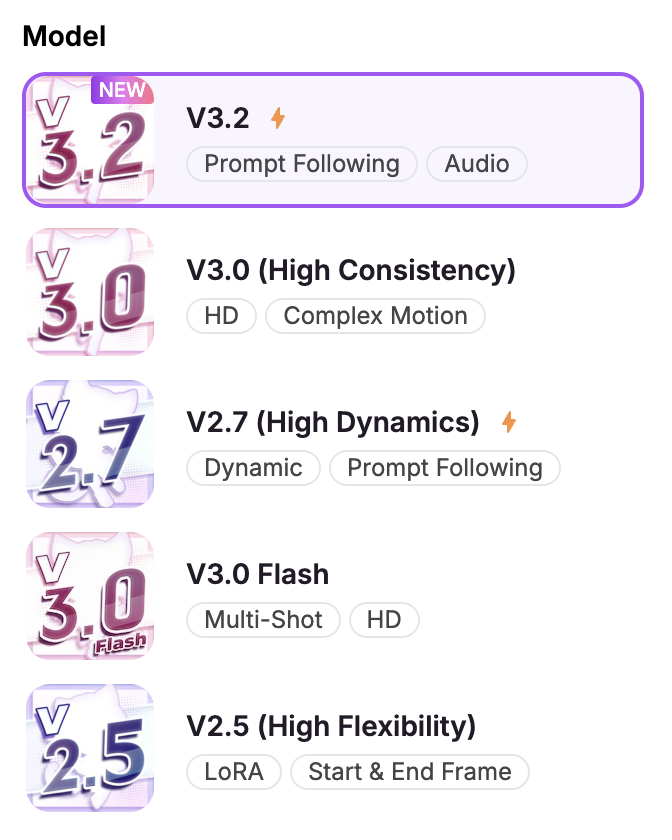
- 右側面板(核心控制區):各模型的設定選項會有所不同。例如:v3.0 (高一致性) 提供更豐富的動作預設,包含多種舞蹈選項;v3.2是目前唯一支援音訊 生成的模型;v2.7 (高動態)獨家支援鏡頭控制功能。
- 模式(Mode):
- 專業 (Professional): 高畫質產出(推薦)。
- 基礎 (Basic): 處理速度較快。

- 時長: 可選擇 5 秒或 10 秒動畫。雖然長影片看起來很厲害,但對模型渲染的穩定度挑戰也較大。若在測試創意或調整提示詞,建議從 5 秒開始。

- 提示詞框 : 這是魔法發生的地方。請在這裡輸入場景描述,包含主體、動作與環境。
💡 小撇步: 使用AI 智慧提示詞
提示詞框右上角有一個開關,能協助自動優化您的描述以獲得更佳效果。
- 鏡頭控制: 下拉選單提供動態效果,如縮放 (Zoom)、平移 (Pan) 或旋轉 (Spin)。註:仅v2.7 支援此選單功能,在支援的模型中使用能大幅提升影片的電影感。

- 進階設定:
- 負面提示詞: 排除不想要的結果(如:
blurry模糊,disfigured變形)。
- 負面提示詞: 排除不想要的結果(如:

- 動作預設 (Action Presets): 提供「親吻」或「擁抱」等快速捷徑,適合提示詞新手。
模型陣容總覽
v3.2 — 電影級音訊敘事者
v3.2 是專為追求「完整故事片段」而非單純動態的創作者所打造。它結合了強大的提示詞遵循能力與流暢的電影感動作,並加入原生音訊 (Native Audio) 功能,讓您的場景能發聲、有呼吸感。這款模型非常適合製作會說話的肖像、角色獨白,或是需要音效來增強感染力的氛圍感場景。
最適合: 說話片段、敘事場景、大氣的劇情呈現、具有「最終剪輯」質感的產出。
v3.0 (高一致性) — 穩定優先的首選
這款模型的核心目標在於「不跑型」。v3.0 (高一致性) 專注於在整個影片片段中保持臉部、服裝和整體風格的高度穩定,減少突然跳變或「角色崩壞」的情況。其動態表現傾向於自然而非誇張,有助於維持令人信服的視覺連貫性。
實戰建議: 對於角色系列作、需要維持視覺身份一致性,以及穩定度比戲劇化運鏡更重要的場景,這是最保險的選擇。
v2.7 (高動態) — 電影級專業模型
這是我們的旗艦級電影感模型,具備以下特色:
- 進階鏡頭運動模擬: 能夠精準模擬專業攝影機的運鏡軌跡。
- 電影級動態模糊與景深效果: 賦予影像更深邃的空間感與速度感。
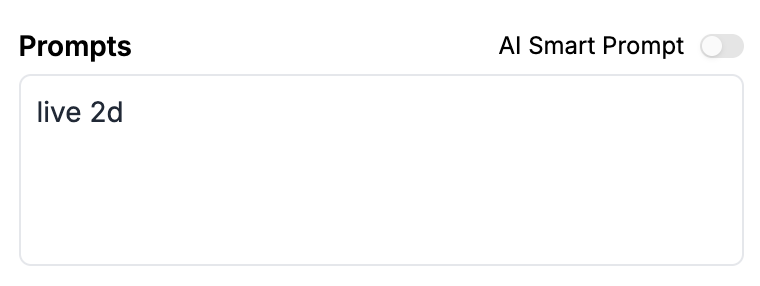
- 支援簡易提示詞運鏡: 即使只輸入
live 2D這種簡單的提示詞,它也能自動賦予動態運鏡,讓簡單的輸入也能產生極具張力的結果。
v2.7 (高動態) 旨在提供視覺效果強烈、如同電影大片般的體驗。它擅長處理複雜場景、層次分明的深度感以及大幅度的相機位移,是進行具有動態構圖與敘事需求創作的最佳選擇。
v3.0 Flash — 給快速迭代者的速度之王
v3.0 Flash 是為「動能」而生的模型。當您正在測試創意、精煉提示詞,或需要透過多次嘗試來構建分鏡序列時,Flash 憑藉極快的生成速度和靈活的電影結構(包含多鏡頭切換與轉場風格)讓您的工作流程不中斷。
應用場景: 把它當作您的「草稿與探索」模型:大量生成、多方嘗試、鎖定構思後,如有需要再進行最後磨光。
v2.5 (高靈活性) — 寫實動態模型
當靈活性與風格多樣性最為重要時,v2.5 是您的首選模型。它能駕馭極廣的視覺美學,特別擅長捕捉細微動作、豐富的面部表情,以及在不同提示詞下展現符合物理邏輯的互動。
雖然在處理跳舞或奔跑等複雜動作時,可能需要多生成幾次才能達到完美,但它遵循細節提示詞的能力,以及維持寫實光影與質感的特點,使其成為製作具表現力與高度客製化影片的強大工具。
- 細膩與動態兼具: 能夠表現角色細微的表情變化與大幅度的肢體動作。
- 豐富的面部微表情: 捕捉眼神與嘴角等細微的肌肉運動。
- 物理真實感: 在不同風格間皆能維持可信的光影、陰影表現與物理互動。
獨家功能: 目前只有 v2.5 支援影片 LoRA (Video LoRA),可用於特定動作、舞蹈、Live 2D 或震動效果。我們未來將發布更多影片 LoRA,並開放讓您訓練專屬影片 LoRA 的功能。
掌握提示詞撰寫
現在來到最關鍵的部分——撰寫真正有效的提示詞。與其只給您範例,我們更想解釋每個技巧背後的「為什麼」,讓您能創作出屬於自己的高效提示詞。
一份優秀的提示詞通常遵循以下結構: 提示詞 = 主體 (Subject) + 動作 (Motion) + 環境 (Environment)
讓我們從您的錨點開始,逐層拆解:
第一層:主體定義
既然您使用的是「影像轉影片」,主體在視覺上已經存在,因此不需要過於詳細的角色描述。但仍需在提示詞中加入主體的大致描述,為什麼? 因為這能幫助模型鎖定髮型、服裝或五官等「視覺錨點」,特別是在動作過程中維持一致性。
- 範例: 「一位白髮、貓耳、紫瞳的少女」
每個描述詞都給了 AI 特定特徵,讓它在動畫過程中進行追蹤與維持。
第二層:動作規範
這是動畫的靈魂。您在告訴模型主體正在做什麼,因此必須具體且有目的性。務必將動作與主體連結。這為什麼重要? 因為這能給模型一個明確的動作目標,以及該「如何」進行動畫處理。
✅ 好範例:
「白髮少女用一隻手輕輕整理瀏海,頭部微微傾斜。」
❌ 應避免模糊動作,如:
「她四處移動」
建議改寫為:
「她緩慢地向前傾身,撫摸膝蓋上的貓,隨著貓咪發出呼嚕聲,她的表情也變得柔和。」
撰寫小撇步:
- 使用帶有動作感與風格的動詞(例如:「優雅地躍起」、「快速地瞥一眼」、「帶著遲疑地旋轉」)。
- 避免單獨使用「移動」或「互動」等抽象詞彙。
- 將物理動作與情緒細節或節奏感結合。
第三層:環境脈絡
模型也需要知道主體身在何處——這有助於它套用正確的光影、反射、氛圍,甚至是物理效果(如風吹或微粒)。
✅ 好範例:
「坐在沐浴在午後陽光的木製教室課桌旁,塵埃微粒在金光中飛舞。」
或:
「黎明時分站在霧氣繚繞的湖邊,柔和的光線反射在水面上。」
這能幫助模型模擬光影變化、大氣壓力與背景互動。
第四層:鏡頭運動 — 非必填
想要電影感?加入鏡頭控制吧。但請保持務實——許多模型僅支援基礎運動,而進階運鏡在 v3.0 或 v2.7 中支援得更好。
提示詞 = 鏡頭運動 + 主體 + 動作 + 環境 + 鏡頭語言
鏡頭提示詞告訴 AI 如何取景以及如何在場景中穿梭。撰寫時,請像導演一樣思考:描述您希望攝影機如何物理性地在空間中導航,無論是向前滑行、向上傾斜還是橫向平移。
關鍵建議:
放置位置: 最重要的是,將鏡頭指令直接放在場景描述中動作發生的位置。例如:「鏡頭緩慢推過人群朝向少女,當她抬頭看著離境告示牌時,過渡到過肩鏡頭。」這樣 AI 就能精確理解何時執行動作而不會產生混淆。
考慮時機: 避免過於複雜的編舞,讓 AI 能乾淨地執行。
鏡頭運動工具箱
| 運動類型 | 提示詞語法 (Prompt Syntax) | 最佳使用場景 |
| 推鏡頭 (Push In) | camera slowly pushes in from [wide/medium] to [close-up] | 情感揭示、特寫 |
| 拉鏡頭 (Pull Back) | camera pulls back to reveal [context/environment] | 交代大環境背景 |
| 橫移 (Pan) | camera pans smoothly from left to right | 展現全景、地景掃描 |
| 俯仰 (Tilt) | camera tilts up from [feet/ground] to [face/sky] | 角色登場介紹 |
| 環繞 (Orbit) | camera orbits around the subject [clockwise] | 動態展示角色全貌 |
| 跟鏡 (Track) | camera tracks alongside as [subject] moves | 跟隨動作進行 |
| 升降 (Crane) | camera cranes up from ground level to bird's eye view | 戲劇性的規模感改變 |
| 移動攝影 (Dolly) | smooth dolly shot moving [forward/backward] | 電影感的接近或遠離 |
您準備好擔任導演,為您的圖片執導第一場戲了嗎?